AI and Confidential Information — A Practical Classification Guide
By LumaVista Team


“Can I paste this into ChatGPT?” You’ve heard it. You’ve asked it. Maybe you asked it this morning. And the honest answer is: it depends on what you’re pasting in.
The problem is that most organizations answer this question with one of two extremes. Either “never use AI with company data” — which everyone ignores because AI is genuinely useful — or “sure, go ahead” with no guidance at all. Both approaches fail. The first one drives usage underground into shadow AI. The second one puts sensitive information on servers you don’t control.
There’s a better way. You classify your data first, then match it to the right tool. Here’s a framework that makes that decision simple enough to print out and keep at your desk.
The answer is not a single rule — it is a classification system that matches the tool to the sensitivity of the data.
Note: This article provides a practical framework for thinking about AI and data sensitivity. It isn’t legal advice or compliance certification. Your organization’s specific regulatory obligations, industry requirements, and risk tolerance should shape your final policy. When in doubt, involve your legal and compliance teams.
Why blanket rules always fail
A hospital researcher wants to use AI to summarize publicly available clinical trial results. A marketing analyst wants to generate social media copy from the company blog. A lawyer wants to check contract language against a template. These are three completely different risk profiles, but a blanket “no AI” policy treats them identically.
The researcher is working with public data — there’s zero risk in pasting published abstracts into any AI tool. The marketing analyst is working with internal content that’s headed for publication anyway — low risk, but you’d want an approved tool with sensible retention policies. The lawyer is working with privileged information that could waive legal protection if disclosed to a third party — that data shouldn’t touch any external AI system, period.
Blanket rules fail because they ignore this spectrum. “Never use AI” frustrates people working with harmless data and pushes them toward unapproved tools. “Always use AI” gives no guidance to people handling genuinely sensitive information. The answer isn’t a single rule — it’s a classification system that matches the tool to the sensitivity.

The four levels
This framework uses four classification levels. If your organization already has an information classification policy (and it should), these map directly to what you’re already doing. If you don’t have one yet, this is a solid starting point.
Level 1: Public
What it is: Information that’s already publicly available or intended for publication. Press releases, published blog posts, marketing copy, open-source documentation, publicly filed documents, product specifications that are on your website.
Which AI tools you can use: Any of them. ChatGPT, Claude, Gemini, Copilot, open-source models — whatever gets the job done. There’s no confidentiality risk because the data is already public.
Policy requirement: None beyond your organization’s general acceptable-use guidelines.
Level 2: Internal
What it is: Business information that isn’t public but wouldn’t cause significant harm if disclosed. Internal memos, draft presentations, meeting notes, project timelines, organizational charts, general process documentation. It’s the kind of information you wouldn’t post on your website but also wouldn’t panic about if it leaked.
Which AI tools you can use: Approved enterprise tools with data protection agreements. That means tools where your organization has a contract that covers data handling, retention limits, and a commitment that your inputs won’t be used for model training. The enterprise tiers of ChatGPT, Claude, and similar tools typically offer these protections — but read the actual agreement, don’t assume.
Policy requirement: Use only tools on your organization’s approved list. Verify that the tool’s data processing agreement covers your jurisdiction’s requirements.
Level 3: Confidential
What it is: Information that would cause real harm if disclosed. Customer data, employee records, financial projections, trade secrets, strategic plans, M&A discussions, proprietary algorithms, unpublished research results, and anything covered by NDA.
Which AI tools you can use: Sovereign AI infrastructure only. That means AI systems running entirely within your legal jurisdiction — for EU organizations, that means EU-hosted infrastructure operated by an EU-headquartered company with no US parent corporation. Why the emphasis on parent company? Because the CLOUD Act gives US law enforcement the ability to compel US-headquartered companies to hand over data stored anywhere in the world, regardless of where the servers sit. EU-hosted doesn’t mean EU-controlled if the company answering subpoenas is in San Francisco. We cover this distinction in detail in Your Data and AI.
Policy requirement: Documented data processing agreement with sovereign guarantees. Data residency within jurisdiction. No training on your inputs. Encryption in transit and at rest. Audit logs.
Level 4: Privileged / Regulated
What it is: Information with the highest level of legal protection. Attorney-client privileged communications, patient health records under HIPAA, data subject to active regulatory investigation, classified government information, information under court seal, and certain categories of financial data under banking secrecy laws.
Which AI tools you can use: On-premise or air-gapped AI systems only — or no AI at all. This data is so sensitive that even sovereign cloud infrastructure may not meet the requirements. Privileged information that passes through any third-party system, even a trusted one, risks waiving the legal protection that makes it privileged in the first place.
Policy requirement: On-premise deployment with no external network connectivity. Full audit trail. Legal review before any AI processing. In many cases, the correct answer is simply: don’t use AI for this.
The decision tree
Before you paste anything into an AI tool, run through these questions:
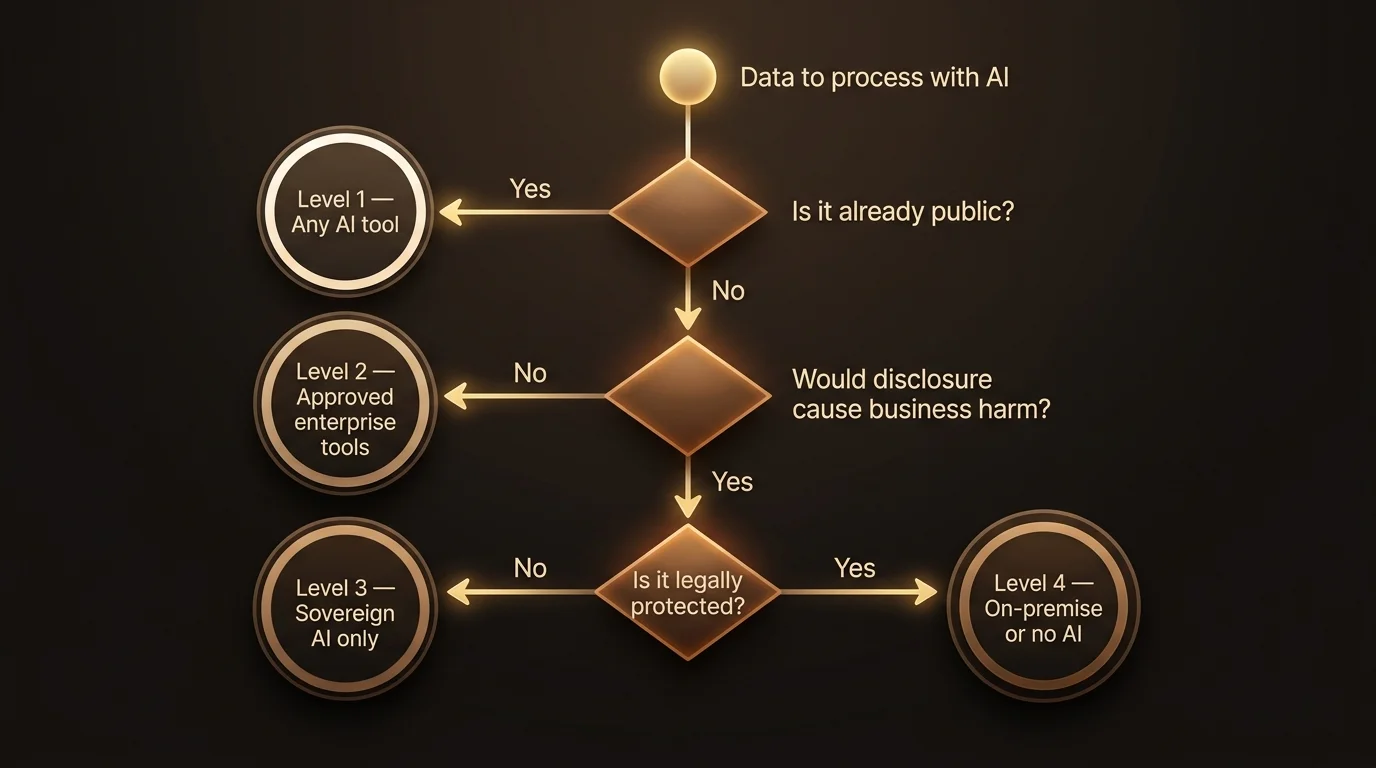
1. Is this information already public? (published, filed, on your website)
- Yes → Level 1: Any AI tool
- No → go to question 2
2. Would disclosure cause real business harm? (customer data, trade secrets, financials)
- No → Level 2: Approved enterprise tools
- Yes → go to question 3
3. Is this legally protected? (privilege, HIPAA, court seal, banking secrecy)
- No → Level 3: Sovereign AI only
- Yes → Level 4: On-premise or no AI
When you’re unsure which level something falls into, go one level up. Treating internal data as confidential wastes a bit of convenience. Treating confidential data as internal can waste your business.
How this maps to existing standards
You don’t need to invent a classification system from scratch — established frameworks already exist, and this four-level approach aligns with them.
ISO 27001 (Annex A, Control A.8.2) requires organizations to classify information based on legal requirements, value, and sensitivity, then apply appropriate labeling and handling procedures. The standard doesn’t prescribe specific levels, but most implementations use three to five tiers that map cleanly to Public / Internal / Confidential / Restricted.
NIST SP 800-60 provides guidance for categorizing information and systems by impact level — low, moderate, and high — based on the potential damage from unauthorized disclosure, modification, or loss of availability. A “low” impact rating aligns with our Public and Internal levels. “Moderate” maps to Confidential. “High” maps to Privileged/Regulated.
If your organization already follows either framework, adopting this AI classification is straightforward: use your existing data labels to determine which AI tools are permitted for each category. You’re not adding a new system — you’re extending the one you already have to cover a new category of tooling.

EU-hosted does not mean EU-controlled if the company answering subpoenas is headquartered in San Francisco. Data residency is not sovereignty.
Common mistakes that bypass your classification
Even with a clear framework, people find ways to accidentally circumvent it. Here are the patterns that trip organizations up most often.
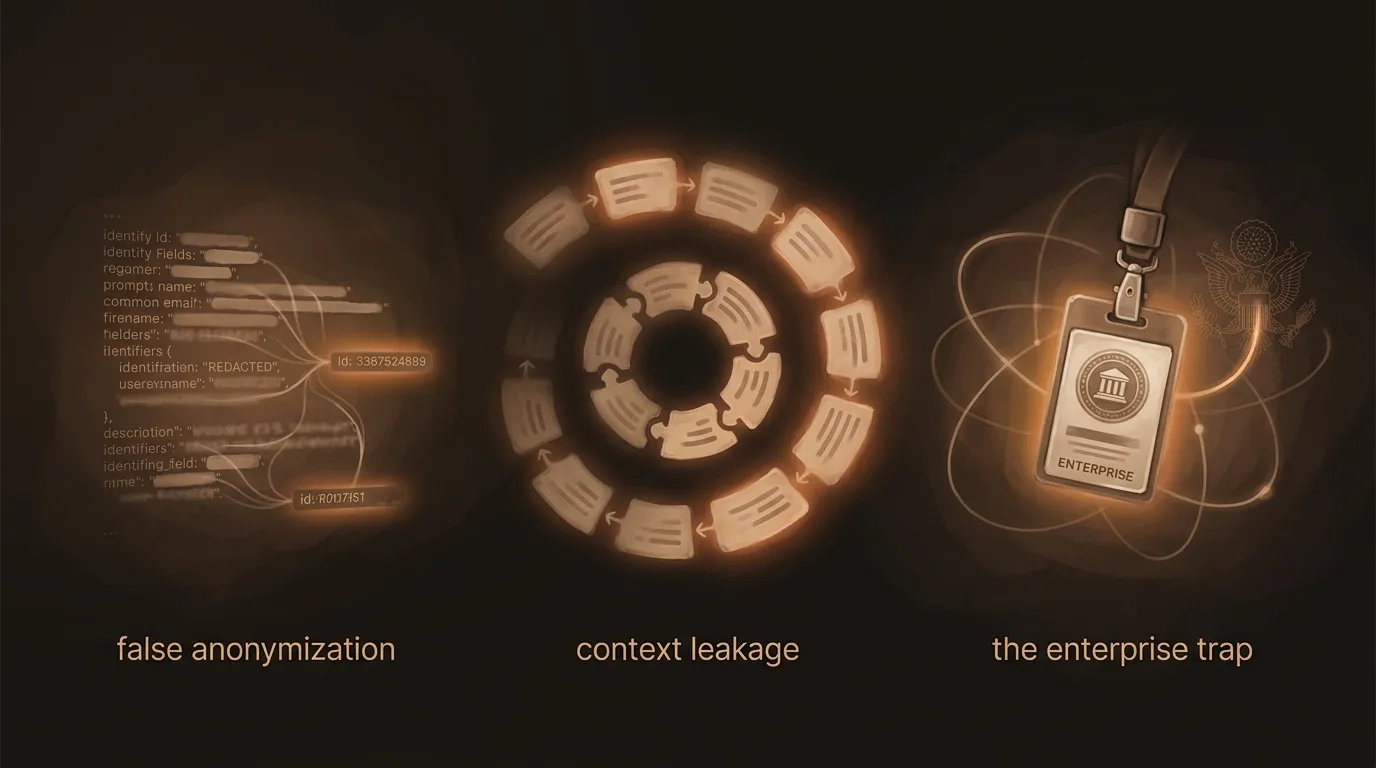
”I’ll just anonymize it first”
This is the most dangerous misconception in data privacy. People assume that removing names and email addresses makes data safe to paste into any AI tool. It doesn’t.
Researchers have repeatedly demonstrated that supposedly anonymized datasets can be re-identified with surprisingly little effort. A landmark study by Arvind Narayanan and Vitaly Shmatikov showed that anonymous Netflix viewing histories could be de-anonymized by cross-referencing them with public IMDb reviews. Later work by Yves-Alexandre de Montjoye and colleagues demonstrated that just four spatiotemporal data points were enough to uniquely identify 95% of individuals in a dataset of 1.5 million mobile phone users.
Just four spatiotemporal data points are enough to uniquely identify 95% of individuals in a dataset of 1.5 million people. Removing names does not make data anonymous.
The bottom line: stripping obvious identifiers doesn’t make data anonymous. If the underlying data is Confidential or Privileged, treat it that way regardless of what you’ve removed.
”I’m just asking a general question”
“I’m not sharing any data — I’m just asking the AI a general question about our contract structure.” Except the question itself often reveals sensitive context. Asking “what are the tax implications of acquiring a company in Germany for €46M” tells the AI — and anyone who might later access your conversation logs — that your organization is considering a specific acquisition at a specific price point in a specific market.
Context leakage is subtle. Each individual prompt might seem harmless, but a sequence of related prompts can paint a detailed picture of confidential plans. Treat the context of your questions with the same sensitivity as the data itself.
”I’m using the enterprise plan”
Enterprise doesn’t mean sovereign. Enterprise AI plans typically guarantee that your data won’t be used for model training and provide contractual data processing agreements. That’s genuinely important — it puts you in Level 2 territory. But enterprise plans from US-headquartered providers still run on infrastructure subject to US jurisdiction, which means the CLOUD Act applies. For Level 3 (Confidential) data, enterprise isn’t enough. You need sovereign infrastructure.
What sovereign AI actually means
“Sovereign AI” gets thrown around a lot, and half the time it just means “we have servers in the EU.” That’s data residency, not sovereignty. Here’s what each level actually requires.
For Confidential data (Level 3): Sovereign means the AI infrastructure is hosted entirely within your legal jurisdiction, operated by a company headquartered in that jurisdiction, with no parent company or controlling entity outside it. The data processing agreement is governed by local law. Your inputs aren’t used for training. The encryption keys are under your control or held by a provider subject only to your jurisdiction’s courts. For EU organizations, this means an EU-headquartered provider, EU-only infrastructure, and no CLOUD Act exposure through a US parent company. We break this down further in Data Sovereignty Is Not Data Residency.
For Privileged/Regulated data (Level 4): Sovereign isn’t enough. This data needs on-premise deployment — AI models running on hardware you physically control, with no external network connectivity. Air-gapped. No cloud component at all. If the data is attorney-client privileged, running it through any third-party system, even a sovereign one, risks an argument that you’ve waived privilege by disclosing to a third party. If it’s under regulatory investigation, any external processing creates chain-of-custody questions you don’t want to answer.
Quick-reference table
| Level | Example data | Allowed tools | Policy requirement |
|---|---|---|---|
| 1 — Public | Press releases, published content, open-source docs | Any AI tool | General acceptable use |
| 2 — Internal | Meeting notes, drafts, org charts, project timelines | Approved enterprise AI with DPA | Approved tool list, data processing agreement |
| 3 — Confidential | Customer data, financials, trade secrets, NDA material | Sovereign AI only (jurisdiction-hosted, no US parent) | Sovereign DPA, data residency, no training, encryption, audit logs |
| 4 — Privileged | Attorney-client comms, HIPAA data, court-sealed info | On-premise / air-gapped only, or no AI | Legal review, on-premise deployment, full audit trail |
What to do now
-
Classify your most common AI use cases. List the five things your team pastes into AI tools most often. Assign each one a level. You’ll probably find that most daily use falls into Level 1 or 2 — which is good news.
-
Check your enterprise agreements. If you’re paying for an enterprise AI plan, read the data processing agreement. Confirm whether your inputs are used for training, where data is processed, and which jurisdiction’s law governs the contract.
-
Identify your Level 3 data. What information does your organization handle that would cause real harm if disclosed? Customer databases, financial models, strategic plans, IP — make a list. This is the data that needs sovereign infrastructure.
-
Audit your current tools against the levels. For each AI tool your organization uses, determine what level of data it can safely handle. Most consumer and enterprise US-provider tools cap out at Level 2.
-
Write it down. Turn your classification into a one-page reference that every employee can follow. Tape it to the wall, put it in the onboarding deck, make it part of your AI policy framework.
-
Set up a sovereign option for Level 3. If your organization handles confidential data — and almost every organization does — you need an AI tool that meets sovereign requirements. LumaVista provides EU-sovereign AI infrastructure with device-level encryption and no US company in the data path, purpose-built for the confidential tier.
-
Review quarterly. Data classifications change. A product roadmap that’s Confidential today becomes Public after launch. An internal draft becomes Confidential when it includes customer feedback. Build a review cycle so your classifications stay current.